Reward capability comes from evolving an external library of Skills & Tools — the underlying VLM stays frozen.
Learns from ~100 preference examples instead of the 200K typically used to train reward models — no extra human annotation.
47.4% avg accuracy on EditReward-Bench + GenAI-Bench; a stronger reward signal for GRPO than EditReward.
Abstract
Evaluating instruction-guided image edits requires rewards that reflect subtle human preferences, yet current reward models typically depend on large-scale preference annotation and additional model training. This creates a data-efficiency gap: humans can often infer the target evaluation criteria from only a few examples, while models are usually trained on hundreds of thousands of comparisons.
We present RewardHarness, a self-evolving agentic reward framework that reframes reward modeling as context evolution rather than weight optimization. Instead of learning from large-scale annotations, RewardHarness aligns with human preferences by iteratively evolving a library of tools and skills from as few as 100 preference demonstrations. Given a source image, candidate edited images, and an editing instruction, an Orchestrator selects the most relevant subset of tools and skills from the maintained library, and a frozen Sub-Agent uses them to construct a reasoning chain that produces a preference judgment.
By comparing predicted judgments with ground-truth preferences and analyzing successes and failures in the reasoning process, the Orchestrator automatically refines its library of tools and skills without additional human annotation. Using only 0.05% of the EditReward preference data, RewardHarness achieves 47.4% average accuracy on image-editing evaluation benchmarks, surpassing GPT-5 by 5.3 points. When used as a reward signal for GRPO fine-tuning, RL-tuned models achieve 3.52 on ImgEdit-Bench.
Method
An Orchestrator evolves a library of Skills and Tools; a frozen Sub-Agent uses them to score edits.
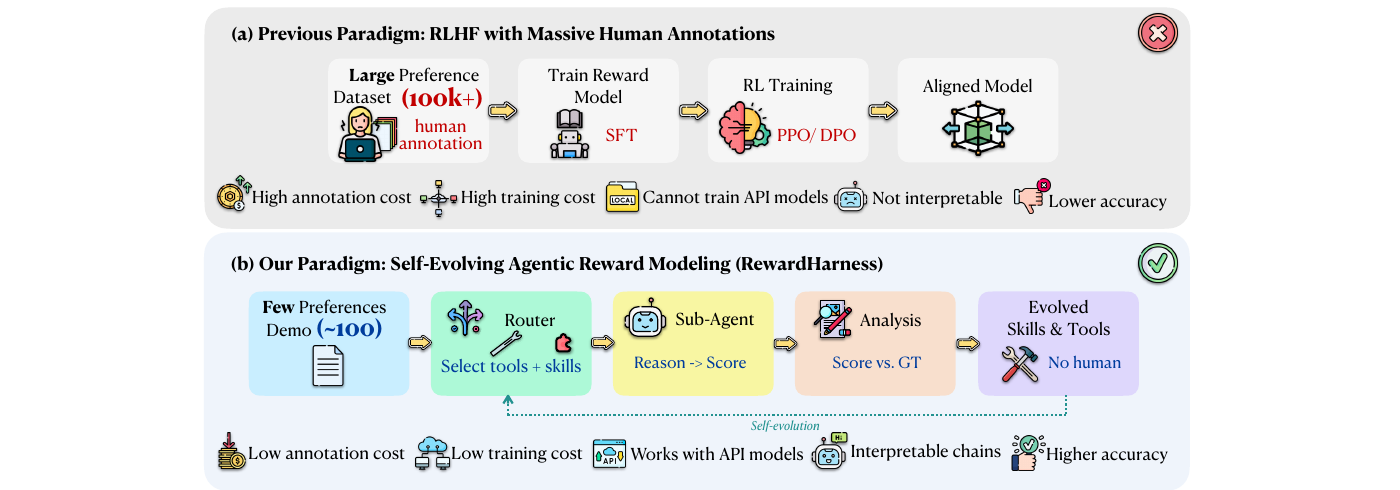
Figure 1 — Paradigm comparison. The conventional paradigm collects large-scale human preference data, trains a reward model, and uses it as the reward signal for RL alignment. In contrast, RewardHarness starts from a small set of preference demonstrations and self-evolves a Skills-and-Tools Library through iterative evaluation and analysis, yielding an interpretable reward system.
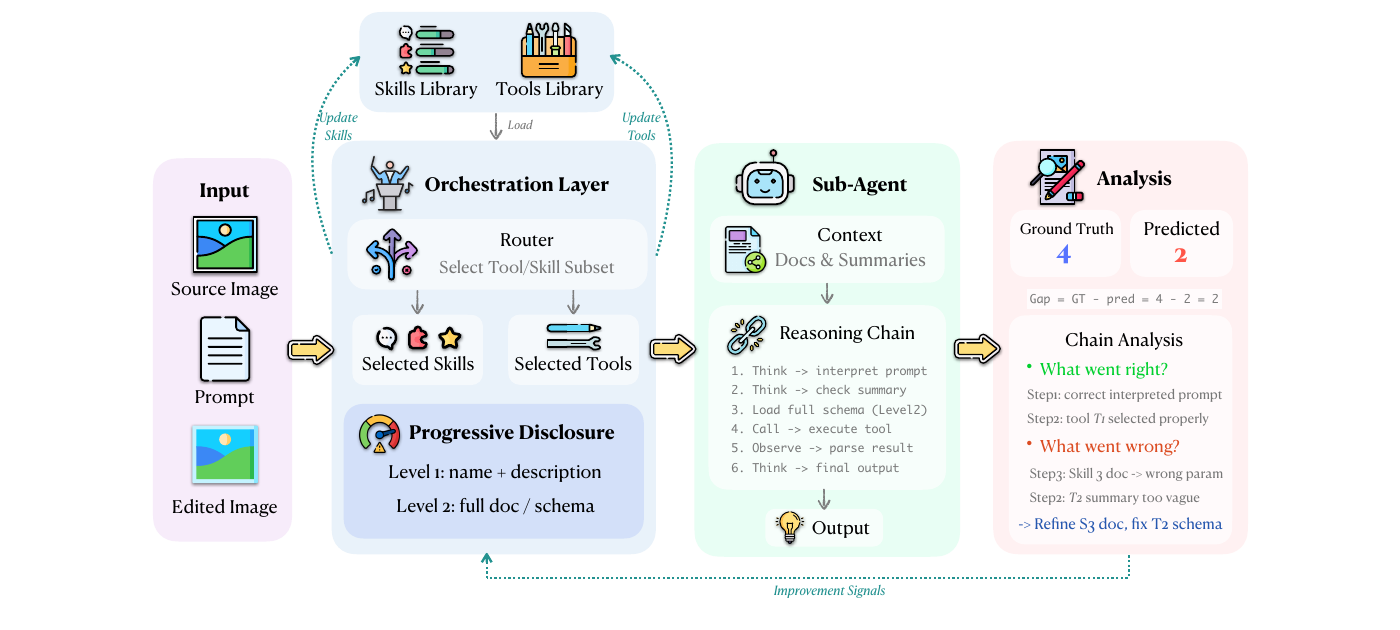
Figure 2 — Self-evolution pipeline. Multi-modal inputs are fed to the Orchestrator, which selects relevant entries from the Skills and Tools libraries. The Sub-Agent (a frozen VLM, e.g., Qwen2.5-VL-7B) builds a reasoning chain that produces scores and a preference judgment. Outputs are scored against ground truth; the Orchestrator analyzes reasoning chains to generate improvement signals that update the libraries.
Orchestrator
A capable LLM that routes the right Skills and Tools from the Library at inference time, then analyzes the Sub-Agent's reasoning chains at evolution time to drive root-cause library updates.
Sub-Agent
A frozen VLM (e.g., Qwen2.5-VL-7B) that reads the selected Skill/Tool documents and constructs a three-stage reasoning chain: rubric application, tool-guided analysis, and aggregation into scores plus a ranking.
Self-Evolution Loop
Each iteration evaluates a train batch, analyzes the Sub-Agent's reasoning chains, proposes library updates, then keeps or rolls back based on a held-out validation gate. Three alternating phases — A: Skills, B: Tools, C: periodic pruning — drive the library forward without catastrophic regressions.
Why it works
Human raters internalize editing-quality criteria from a small calibration set, then apply them consistently at scale. Trained reward models do the opposite — they fit a monolithic scalar from hundreds of thousands of pairs and bury the learned criteria inside opaque weights.
RewardHarness inverts this: it externalizes the evaluation knowledge as readable Skill rubrics and Tool specs, and evolves them with rejection sampling on a 100-example calibration set. The VLM never trains; the Library does. Because failed proposals are gated out by held-out validation, the Library can only get better — while every change remains interpretable, portable across Sub-Agents (Qwen → Gemini), and amenable to manual edits if a reviewer disagrees with the rubric.
Skills and Tools Library
Skills are declarative scoring rubrics; Tools are procedural in-context specifications.

Figure 3 — Skill and Tool examples. Skills are declarative rubrics guiding the Sub-Agent's assessment criteria; Tools are procedural specifications instructing the Sub-Agent to perform targeted visual analysis.
realism-and-artifact-penalties Skill
Guidance on penalizing artifacts while allowing conceptual unrealism if requested by the prompt.
1. Conceptual Unrealism vs. Visual Artifacts: If the prompt requests an inherently surreal ... scenario, DO NOT penalize the image for being conceptually unrealistic. The goal is to follow the prompt. 2. Penalize Visual Artifacts: Only penalize for actual image processing artifacts, such as: bad blending or visible seams, floating objects with missing shadows, distorted textures ... 3. Prioritize Execution Quality: Between two images that follow the instruction, prefer the one with fewer visual artifacts ...
text-and-ocr-analyzer Tool
Extracts and analyzes text within images to verify spelling, placement, and clarity.
input_schema: {images: list[base64_str], query: str}
output_schema: {image_1_text: str,
image_1_spelling_correct: bool, ...}
system_prompt:
"You are an expert OCR and text analysis AI.
Extract all visible text ... Pay strict
attention to spelling, typos, and placement ..."
Use this tool whenever the prompt asks to add
or modify text. It will read the exact spelling
from the images so you can penalize typos or
hallucinations.
What the Sub-Agent thinks
One full reasoning chain — <think> / <tool> / <obs> / <answer> tags as emitted by the frozen Qwen2.5-VL-7B Sub-Agent.
<think> The prompt asks to add a "Sale" sign on the storefront. I need to check three criteria for each candidate: 1. Does the sign actually appear? 2. Is the text spelled correctly? 3. Does the rest of the storefront look unchanged (no over-editing)? Let me call the OCR tool to verify spelling. </think> <tool> {"name": "text-and-ocr-analyzer", "images": ["<base64-A>", "<base64-B>"], "query": "What text appears in each image? Spell it exactly."} </tool> <obs> {"image_1_text": "Sale", "image_1_spelling_correct": true, "image_2_text": "Sael", "image_2_spelling_correct": false} </obs> <think> Candidate A spells "Sale" correctly. Candidate B has a typo ("Sael"). Both sign placements look natural, but B's typo is a clear instruction-following failure for an "add a Sale sign" prompt. The rest of both storefronts look preserved. </think> <answer> { "preference": "A", "score_A_instruction": 4, "score_A_quality": 4, "score_B_instruction": 2, "score_B_quality": 3, "reasoning": "A correctly adds 'Sale'; B has a typo 'Sael'." } </answer>
Only the <answer> block is consumed by the scorer; the rest is interpretable trace.
The Tool call is dispatched only when the prompt's invocation condition matches —
here, "add a sign" triggers text-and-ocr-analyzer.
Try it yourself
The Skill + Tool used in the trace above ship in the repo's
examples/seed_library/.
Score your own edit pair with one command (needs Gemini auth + a Qwen2.5-VL-7B vLLM endpoint):
git clone https://github.com/TIGER-AI-Lab/RewardHarness.git
cd RewardHarness && pip install -r requirements.txt
python examples/score_pair.py \
--source source.png --candidate-a A.png --candidate-b B.png \
--prompt "Add a 'Sale' sign to the storefront" \
--show-chain
--show-chain prints the full <think>/<tool>/<obs>/<answer> trace, exactly like the example above. Or skip the image triplet entirely and reproduce the paper's EditReward-Bench K=2/3/4 numbers against the shipped library: python scripts/run_benchmark.py --config configs/default.yaml (the headline 47.4% average also requires a separate GenAI-Bench pass — see OUTPUTS.md). No GPU? See the
Sub-Agent swap guide
to point at a hosted Gemini-as-Sub-Agent instead.
Key Results
State-of-the-art image-editing evaluation with only 100 preference demonstrations.
Table 1 — Image-editing evaluators on reward benchmarks.
← swipe to see all columns →Best in Indigo bold; second-best underlined. Δ measures average improvement over the GPT-4o baseline. RewardHarness (Gemini-2.0-Flash) achieves the best overall average; RewardHarness (Qwen) outperforms its supervised-finetuned EditReward (Qwen) counterpart by 3.7 points while using only 100 preference examples.
Table 2 — Reward-driven editing on ImgEdit-Bench (FLUX.2-klein-base-4B + RL).
← swipe to see all columns →Under the same GRPO setup, RewardHarness provides a stronger training signal than EditReward, raising the base model from 3.32 to 3.52 on ImgEdit-Bench — matching Flux.1 Kontext [dev] with a significantly smaller backbone.
Qualitative Comparison
Preference judgments on EditReward-Bench — click to enlarge.

Figure 4 — Preference-scoring comparison. Given a source image, editing instruction, and two candidates, RewardHarness assigns the higher score to the human-preferred candidate (marked “GT Winner”), while EditReward picks the wrong one.
Limitations
What RewardHarness doesn't solve yet.
Closed Orchestrator. RewardHarness's Orchestrator relies on a proprietary LLM for routing, chain analysis, and library evolution. While the Sub-Agent is pluggable — we demonstrate Qwen2.5-VL-7B and Gemini-2.0-Flash as drop-in choices — the Orchestrator itself has not been validated with open-source alternatives. This coupling limits full reproducibility and introduces a dependency on API availability and cost.
Single modality, single task. We apply RewardHarness only to instruction-guided image-editing evaluation. Whether the same library-evolution paradigm transfers to other multimodal preference tasks (video editing, audio synthesis, multi-turn dialogue) is open.
Skill plateaus. Skill proposals are accepted less often than Tool proposals during evolution, reflecting the difficulty of modifying declarative rubrics without regression. The library converges to a compact 6-entry final state (3 Skills + 3 Tools) after pruning, which may hide longer-tail failure modes the calibration set never surfaces.
Citation
@article{zhang2026rewardharness,
title={RewardHarness: Self-Evolving Agentic Post-Training},
author={Yuxuan Zhang and Penghui Du and Bo Li and Cong Wei and Junwen Miao and Huaisong Zhang and Songcheng Cai and Yubo Wang and Dongfu Jiang and Yuyu Zhang and Ping Nie and Wenhu Chen and Changqian Yu and Kelsey R. Allen},
journal={arXiv preprint arXiv:2605.08703},
year={2026}
}
Zhang, Y., Du, P., Li, B., Wei, C., Miao, J., Zhang, H., Cai, S., Wang, Y., Jiang, D., Zhang, Y., Nie, P., Chen, W., Yu, C., & Allen, K. R. (2026). RewardHarness: Self-Evolving Agentic Post-Training. arXiv preprint arXiv:2605.08703. https://arxiv.org/abs/2605.08703